About Me
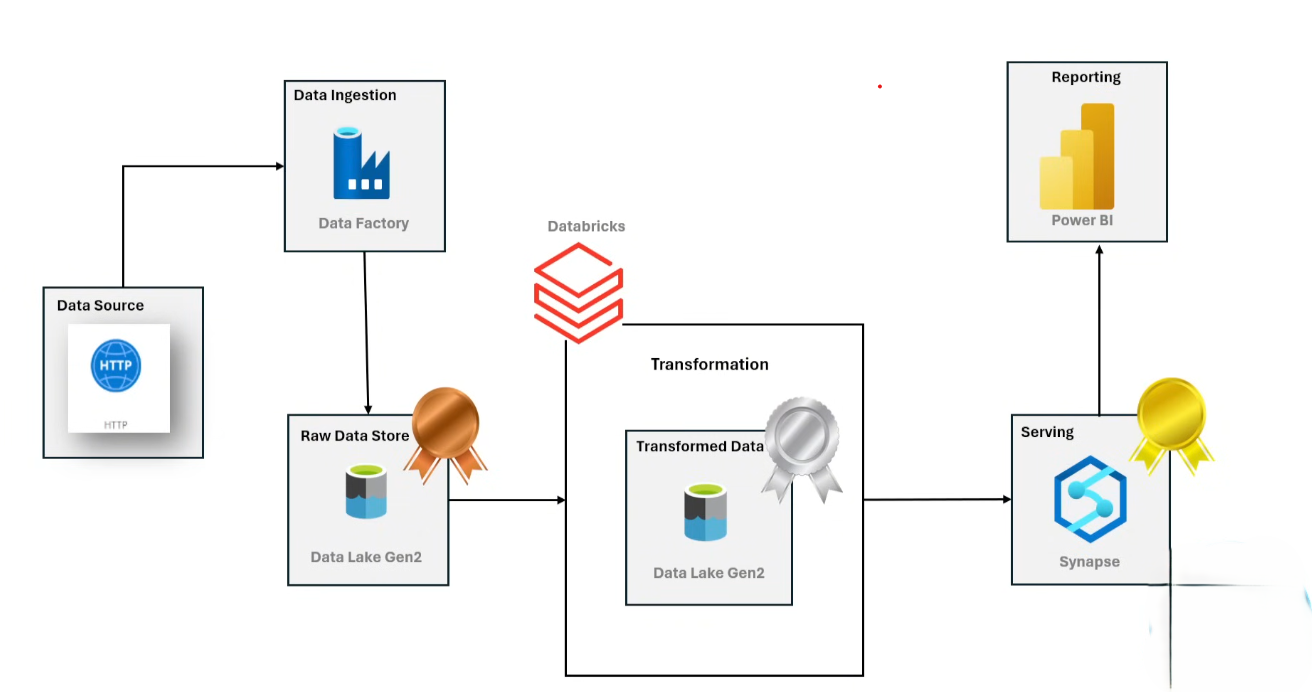
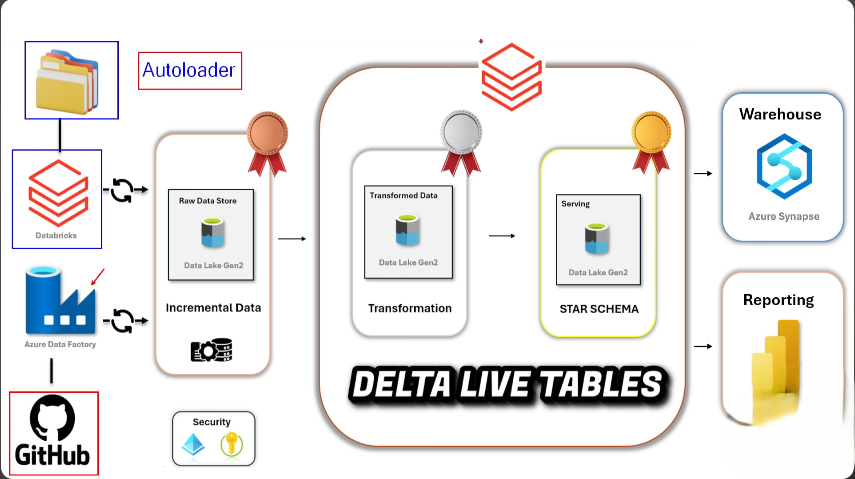
I’m a results-driven Data Engineer with over 1 year of experience designing and building scalable data pipelines, cloud-native architectures, and data analytics solutions. I’m passionate about transforming complex data challenges into elegant, automated, and reliable systems that drive informed decision-making.
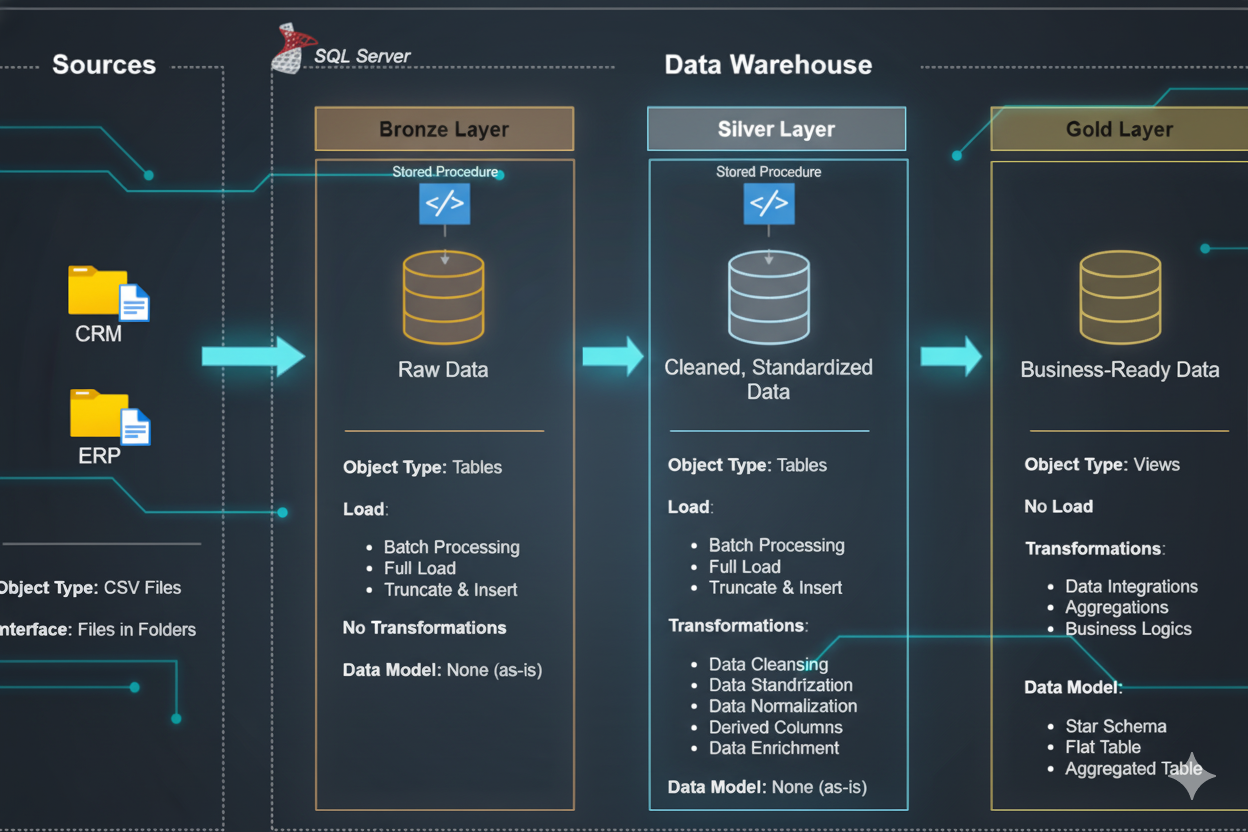
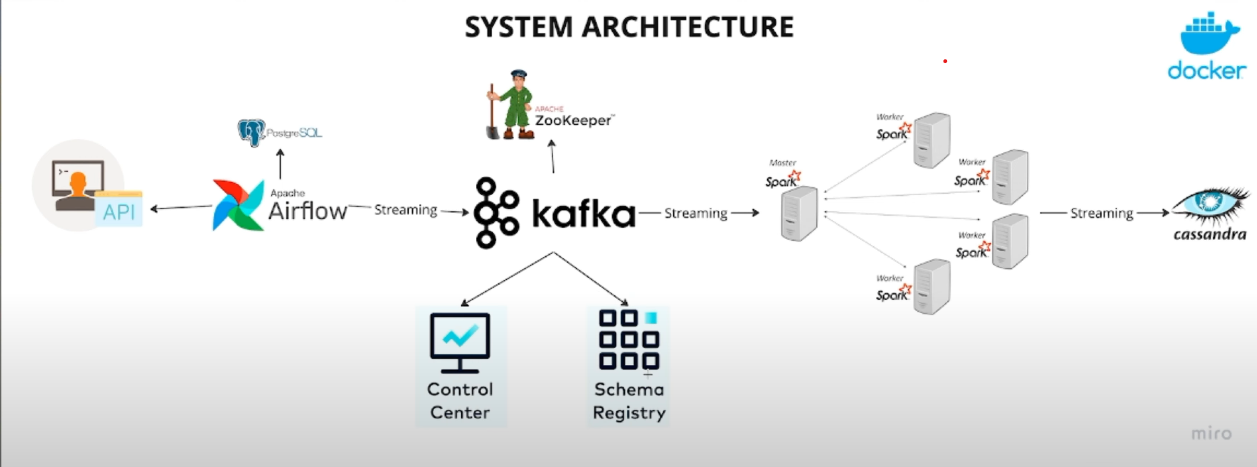
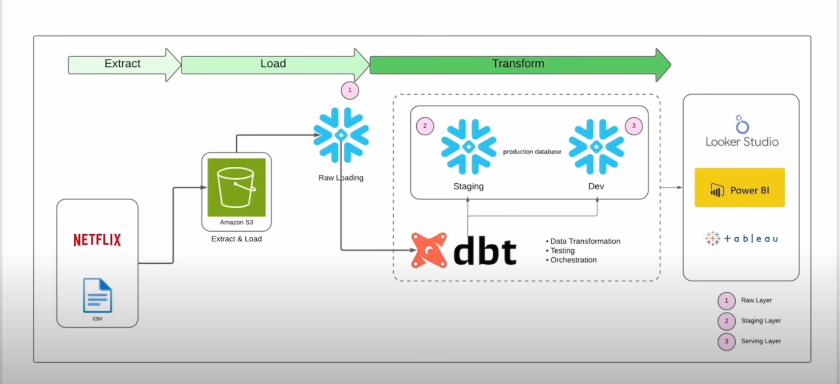
My expertise spans the modern data stack — from ETL/ELT processes and orchestration to data lakes and data warehousing. I thrive in cloud environments like Azure and bring a solid foundation in big data technologies and scalable analytics platforms.
1+ years in data engineering and analytics
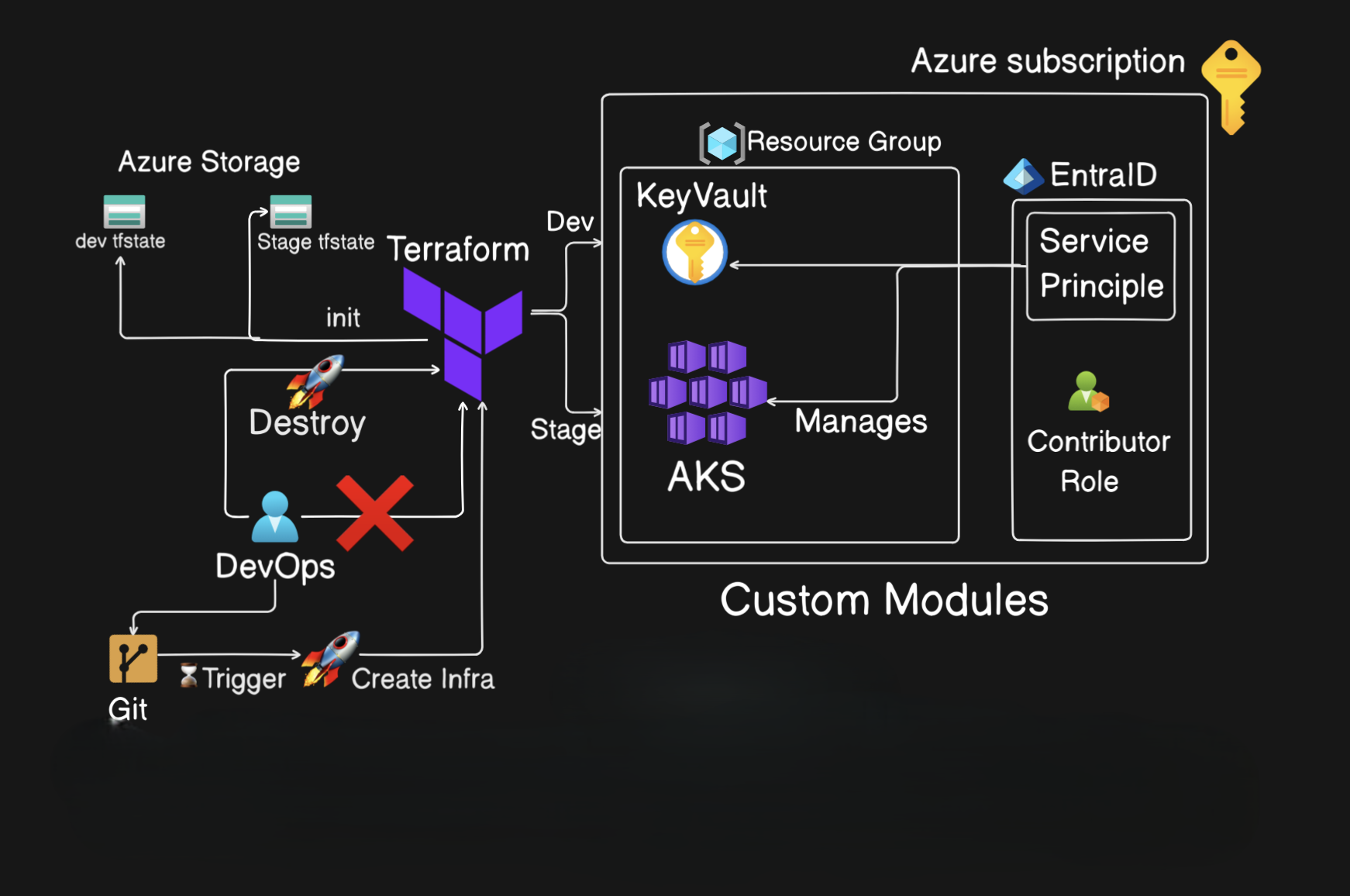
Cloud-native experience in Azure
Specialized in Big data, ETL/ELT, Python and SQL