About Me
I'm a Data Engineer and pan-African innovator with a track record of building data systems that matter. I've represented Kenya at Carnegie Mellon University's AI programme, led cross-border teams across the Afretec network, and earned recognition — including a Silver Award, seed funding, and a CMU-Africa incubation invitation — for work at the intersection of data engineering and social impact.
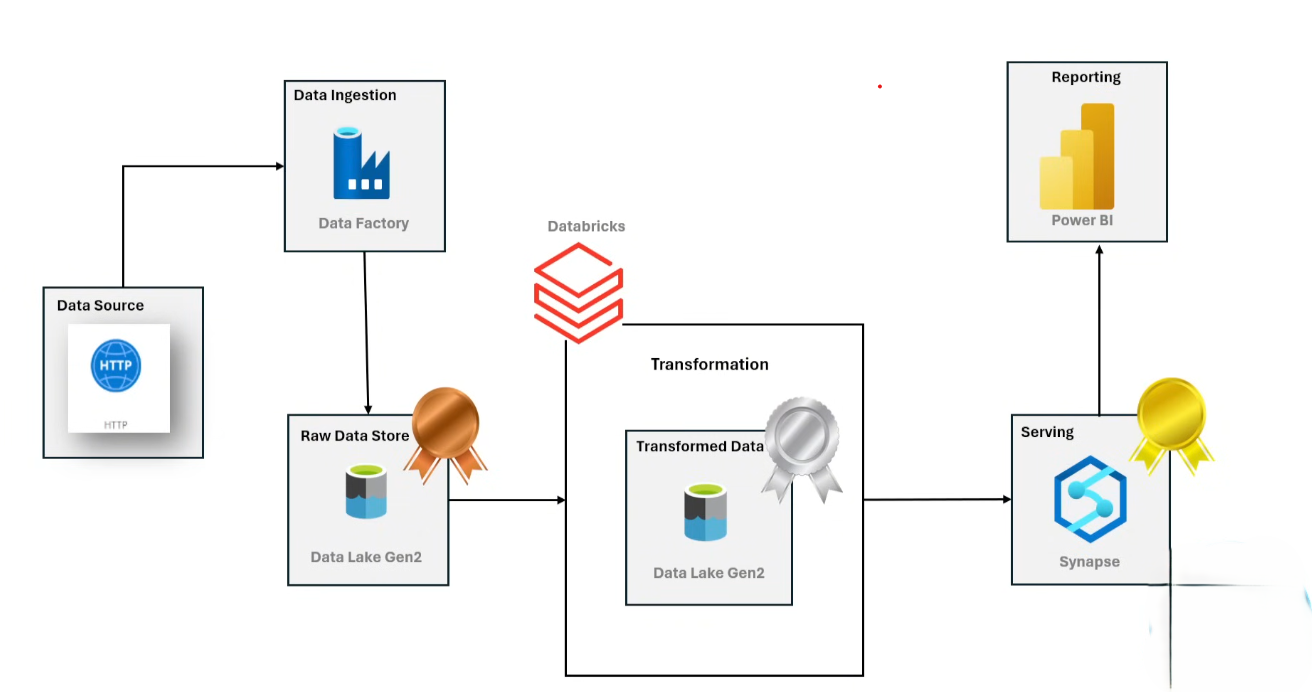
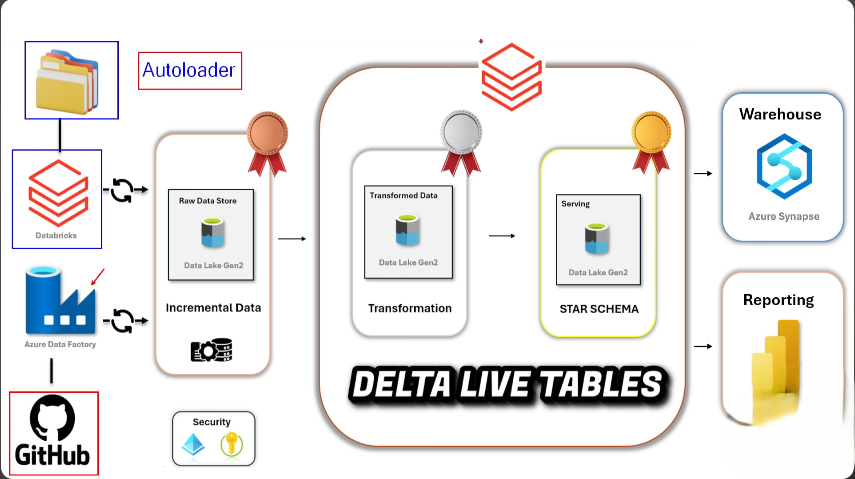
Technically, I specialise in scalable cloud-native pipelines on Azure — from raw ingestion through real-time streaming to analytics-ready models — using tools like Databricks, Kafka, Spark, dbt, and Snowflake. I care about systems that are dependable, observable, and built to last.